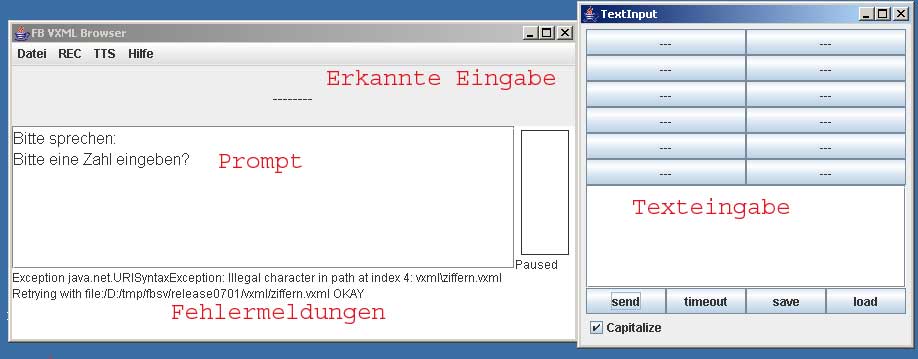
Zum Testen einfacher VoiceXML-Dialoge wurde ein entsprechender Interpreter realisiert. Die Anwendung besteht aus einer Anzahl von Java-Klassen. Spracheingaben und Ausgaben erfolgen über die Audio-Schnittstelle von Java. Für die Spracherkennung wird das HTK-Tool HVite eingesetzt.
Das Hauptziel der Entwicklung war ein einfaches, leicht einsetzbares Programm zur Demonstration grundlegender Möglichkeiten von VoiceXML. Daher wurde Wert gelegt auf:Alle notwendigen Dateien sind als Release in einem Archiv zusammengestellt. Die HTK-Tools und Sprachsynthese werden zusätzlich benötigt. Im Archiv bereits enthalten ist der Open-Source Javascript-Interpreter Rhino.
Nach der Installation sollten im Hauptverzeichnis die Dateien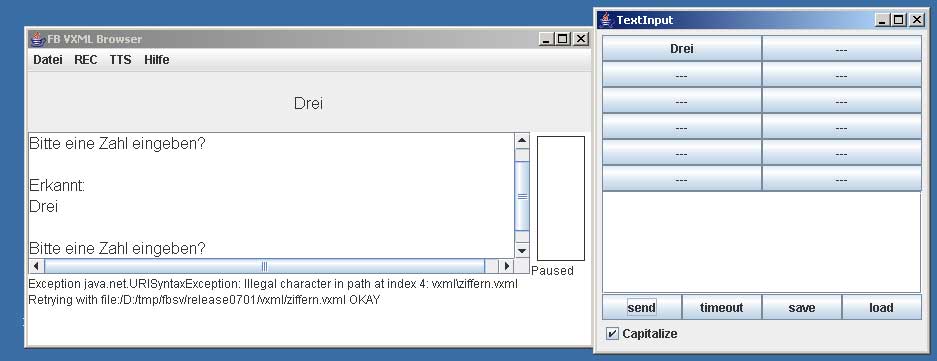
FreeTTS ist eine Java-Implementierung eines Systems zur Sprachsynthese. Die Software ist frei verfügbar. Die Verwendung ist einfach. Das System wird von Sourceforge geholt und entpackt. Dann muss nur noch die Anwendung Server.jar im Verzeichnis bin gestartet werden. FBSV findet dann beim Start den Server und kann ihn für die Sprachsynthese verwenden. Allerdings spricht FreeTTS dann nur Englisch.
Flexibler ist MBROLA. Neben der Software benötigt man Sprecher/innen. Auf der MBROLA-Seite stehen acht verschiedene (de1 bis de8) zur Verfügung. Standard für FBSV ist c:/database/de5/de5. Dies kann mit der Parameter mbrolaDB in der Konfigurationsdatei geändert werden. Zur Umsetzung in die Phonemfolge wird das Programm Txt2Pho verwendet. Ein vom Standard c:/programme/txt2pho abweichendes Verzeichnis muss mit dem Parameter t2pDir in der Konfigurationsdatei eingetragen werden.
<field name="vereine"> <grammar src="net/vereine.net" /> <prompt>Bitte die beiden Vereine eingeben.</prompt> </field>werden die beiden Vereinsnamen erfragt. Das Netzwerk zur Erkennung steht in der Datei net/vereine.net und wurde mit dem HTK-Tool HParse aus der Beschreibung
$city = Bensheim | Biebertal | Dettingen | Eppstein | Friedberg | Fulda | Giessen | Hofheim | Limburg | Marburg | Oberursel | Schoeneck ; ($city $city)(Datei vereine.gram) generiert. In der derzeitigen Version wird die Äußerung zunächst aufgezeichnet und dann mit HVite verarbeitet. Dabei wird entweder ein angegebenes Netzwerk oder ein aus den Angaben in VoiceXML temporär erzeugtes verwendet.
Die Details zur Spracherkennung sind in der ini-Datei festgelegt. In vorliegenden Version sind die Modelle und Listen im Verzeichnis arbeit abgelegt. Es werden einfache Phonem-Modelle zusammen mit einem kleinen Aussprachelexikon verwendet. Um den Wortschatz zu erweitern, müssen entsprechende neue Einträge in das Aussprachelexikon eingefügt werden.
In der gleichen Art und Weise wie die Vereine wird das Ergebnis abgefragt. Schließlich werden die Daten an einen Perl-Skript übergeben. In dem Beispiel sendet der Skript das Ergebnis an die Anwendung Sprachserver (ebenfalls im Archiv enthalten). Weiterhin wird VoiceXML-Code für die weitere Verarbeitung ausgegeben. Die Ausgabe wird in einer Datei submit_tmp.vxml gespeichert. In FBSV wird dann diese Datei als nächstes verarbeitet.