Ein Beispiel für das Training von Hidden Markov Modellen
Benötigte Software:
- HTK
Programme zum Modelltraining etc.
- Perl
Die Skripte zur Steuerung der HTK-Tools sind in Perl geschrieben.
- fbview
Das Programm wird verwendet, um automatisch Listen
mit passenden Äußerungen zu generieren.
Weitere Ressourcen
Für den phonembasierten Erkenner wird noch ein Aussprachelexikon benötigt.
Die Datei dazu - vokabular_pho -
muss später in das richtige Verzeichnis kopiert werden
Sprachdaten und MLFs
Standardmässig liegen die Sprachdaten im Verzeichnis sprachdaten,
aufgeteilt in Referenzen (userdata) und Testdaten (autosave).
Die bei den im Buch beschriebenen Daten können
von hier (Achtung: 70 MB) heruntergeladen werden.
Skripte
Die Perl-Skripte sollten in einem
eigenen Verzeichnis stehen.
Ganzwortmodelle
Die Verzeichnisse mit Sprachdaten und Skripte sollten in ein
gemeinsames Verzeichnis gelegt werden.
Im folgende Beispiel wurde dazu ein Verzeichnis test_htk verwendet.
Das Training wird mit dem Skript all.pl
durchgeführt.
Dieser Skript beinhaltet Aufrufe für die einzelnen Aufgaben.
Über Schalter können einzelne Aufgabe ausgewählt werden.
Sinnvoll ist ein schrittweises Vorgehen, um den Fortschritt
kontrollieren zu können. Im Prinzip läuft alles automatisch ab.
Es werden Verzeichnisse sowie Listen, Grammatiken, etc. erzeugt.
Einige Einstellungen können in den Skripten direkt vorgenommen werden.
Vorgesehen ist, mittelfristig alle Konfigurationsinformationen
zentral zu verwalten. Ein Ansatz dazu ist die Datei hmmconsts.pm.
Von dieser Datei wird eine Kopie in dem Arbeitsverzeichnis erzeugt.
Hier können z. Z. im wesentlichen Anzahl der Zustände und der Dichten
eingestellt werden. Später wird nur noch die Kopie im Arbeitsverzeichnis
verwendet.
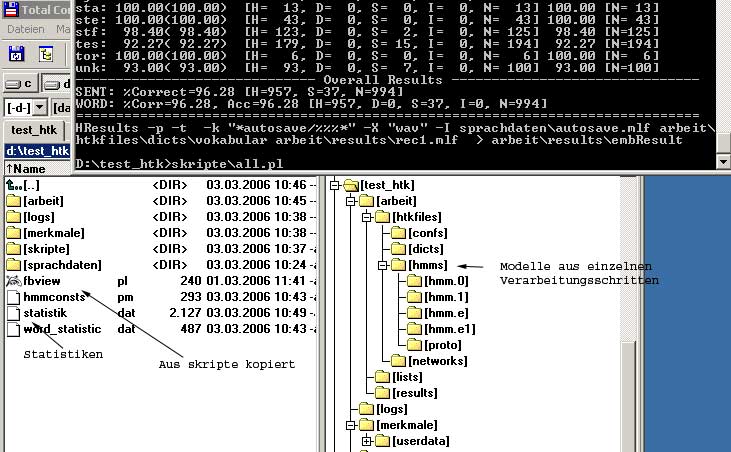
Beim erfolgreichen Durchlauf stehen anschließend in
arbeit\htkfiles\hmms\hmm.e1\digicom
die Wortmodelle.
Insgesamt sollte man folgendes Bild erhalten:
Mit den vorgegebenen Einstellungen - 8 Zustände und 2 Dichten pro Zustand -
resultiert eine Erkennungsquote von 96,28%.
Phonemmodelle
Das Training für Phonemmodelle wird mit dem Skript
phonem.pl gesteuert.
Allerdings sollte zunächst all.pl ausgeführt werden.
Ansonsten
sind beispielsweise noch keine Merkmale berechnet.
Benötigt wird ein Aussprachewörterbuch. Dazu muss die Datei
vokabular_pho in das Verzeichnis
arbeit\htkfiles\dicts\
kopiert werden.
Die Modelle stehen in
htkfiles\hmms\hmm.p1\
Mit den vorgegebenen Einstellungen wird ausgehend von einer Dichte
pro Zustand mit sogenanntem Mixup die Anzahl bis auf 3 erhöht.
Die entsprechenden Modelle sind mit der Endung _1 bis _3 markiert.
Spezial-Skripte
Test der Ganzwortmodelle mit direkter Audio-Eingabe:
do_hvite_live.pl
Bestimmung der Phonemgrenzen und Anzeige mit fbview:
do_align_phonem.pl