Chess moves
As a example for the use of ShowGraph we want to build a network for chess moves. This might be used in a recognizer as speech interface for a chess engine. There are several ways of describing chess moves. We base our example on the Algebraic chess notation. Details on this notation can be found for example at wikipedia. As this is a tutorial on ShowGraph and not on chesss we do no attempt to cover all possibilities.
Basically, the Algebraic chess notation uses a coordinate system to identify each square on the board with eight rows (called ranks) and eight columns (called files). The files are labeled from a to h and the ranks from 1 to 8. Therefore, squares run from a1 (leftmost lower corner of the white player) to h8 (rightmost up corner). The pieces are: king, queen, rook, bishop, knight and pawn.
Details of the move specifications vary. In the long form the piece and both the starting and ending position are specified. Examples are:
- king e3 e4
- queen d8 d1
- pawn c2 c3
In most cases, it is not really necessary to specify the starting position. Just giving the name of a piece and the destination describes a unique move. Furthermore, usually pawns are not named explicitly. In this way the moves given above could be also be specified as:
- king e4
- queen d1
- c3
Building a graph
As a start, we want to build a graph that allows input in the following form:
- optional piece name
- optional start field
- end field
We start ShowGraph without any options:
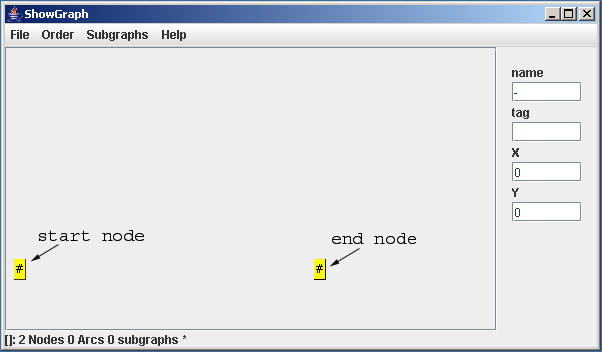
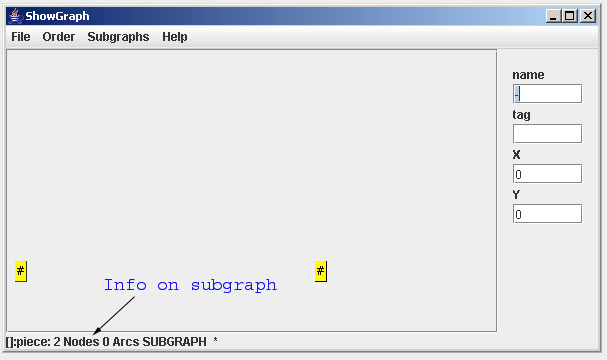
It is a good idea not to implement all in just one large graph but to use so-called subgraphs. A subgraph is like a modul or method in a programming language. A new Subgraph is defined in the NEW item of the subgraphs menu. Let´s start with a subgraph for the pieces. We name this subgraph piece. The ShowGraph automatically shows the new subgraph in it´s main window. Both a start and an end node are already generated. You see some information on the graph in the status line.
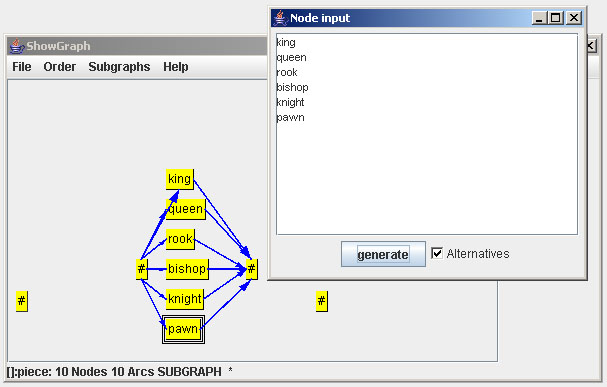
In the piece subgraph the selection of one piece is specified. The network could be build up by inserting indivdual nodes. A simpler way is provided through the Node Input window. The window is opened by choosing the item new Nodes in the context menu. In Node Input you can enter text and let the tool generate the corresponding nodes. Each line of text is considered as a sequence and a node is generated for each word. You can mark these lines as alternatives. Then they are connected through additional start and end nodes. In our case we have only one word, namely one piece, per line. The next screenshot shows the Node Input window and the resulting graph.
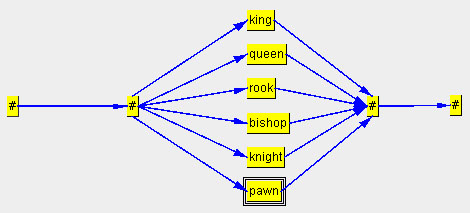
Now we only need to connect the start and end nodes (e. g. with the right mouse). After reordering we obtain:
In the same way we create subgraphs rank and file. Then we have the main graph and three subgraphs. This is very much the same structure as in e. g. a Java class with one main method and a set of other methods. Execution starts with main. In main - and in all other subgraphs - instances of all subgraphs can be included.
Navigation between the subgraphs is provided through the Subgraphs menu. UP leads to the main graph and goto opens a selection of all other graphs. In the main graph we now can build our overall structure. Again we use the Node Input. The following input text covers the possible moves as described above.
[$piece] [$file $rank] $file $rankHere we have two new features:
- $: denotes a subgraph
- []: optional parts
Then the following graph results (again with some rearrangements):
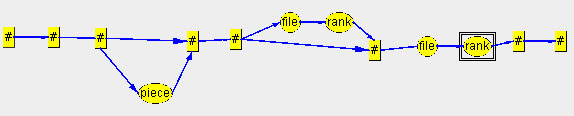
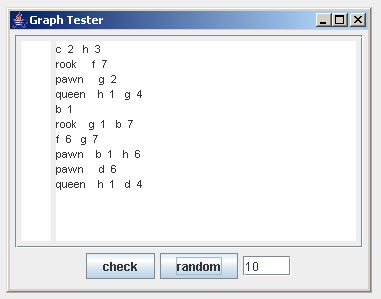
We test the graph with the Tester window (started from the background menu). The example shows ten randomly generated sentences:
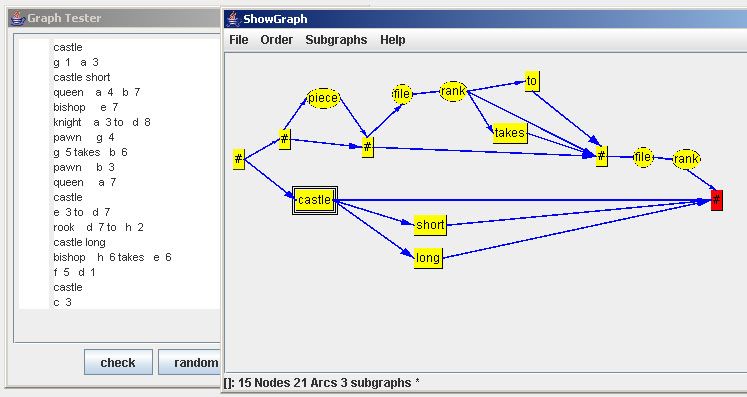
We now can start fine tuning the graph by adding more nodes for further command. Also we can delete some of the extra NULL-nodes. One example - also still not perfect - is the following graph.
Semantic tags
The semantic interpretation of the input sequence is based on tags. Basically, each node - including subgraphs - can have a semantic tag or label. In the recognition process the text corresponding to the node is then assigned to this tag. The random output of the Tester includes the semantic results in braces. Text within braces is ignored when testing a sentence.
In order to demonstrate this mechanism we modify the graph. Firstly, we introduce a new subgraph field that combines rank and file. The field nodes then are labeled either as from or to. Furthermore the piece subgraph is labeled appropriately. The nodes for takes and to have no tags. This leads to the next graph:

Some examples of sentences generated with this graph are:
a 7 {from:a 7 } takes e 4 {to:e 4 }
queen {piece:queen } c 5 {to:c 5 }
g 5 {to:g 5 }
g 2 {to:g 2 }
rook {piece:rook } a 5 {from:a 5 } takes f 1 {to:f 1 }
h 5 {from:h 5 } to f 2 {to:f 2 }
queen {piece:queen } c 2 {to:c 2 }
d 5 {from:d 5 } takes a 1 {to:a 1 }
b 4 {to:b 4 }
In this way the relevant information is extracted. Further processing of the input can use the contents of the semantic tags directly. Unnecessary details of the spoken utterances are discarded.